Lightweight-based Intrusion Event Recognition Method for Distributed Fiber Optic Vibration Sensing
Abstract:
When Distributed Fiber Optic Vibration Sensing (DVS) systems are used for perimeter security intrusion detection in complex industrial environments, existing recognition models suffer from insufficient adaptability, high computational overhead, and high latency. This paper proposes the MNV4-LDA end-to-end recognition method, which integrates the lightweight feature extraction capability of MobileNet-V4 (MNV4) with the advantages of supervised dimensionality reduction of Linear Discriminant Analysis (LDA), constructing a framework from feature enhancement to dimensionality reduction and then to classification. The experiment targets three types of events: background noise, mechanical operations, and human walking. Tests based on 6000 groups of datasets show that the number of parameters of this method is reduced from 632.22M to 2.38M, with a reduction rate exceeding 99.6%. The recognition accuracy reaches 98.28%, 4.67% higher than that of MNV4, and the single-sample inference time on the CPU is 127.0ms. Moreover, no denoising preprocessing is required. This method effectively solves the edge deployment challenges of traditional models, balances efficiency and stability, and provides a practical solution for the edge application of DVS systems in perimeter security.
1. Introduction
Against the backdrop of the growing demand for social security, the identification and prevention of intrusion events in perimeter security face numerous challenges. Traditional security systems such as manual patrols, video surveillance, electromagnetic detection, and infrared alarms have inherent shortcomings, including difficulties in distributed detection and vulnerability to environmental interference. In contrast, the Distributed Fiber Optic Vibration Sensing (DVS) system, leveraging advantages such as long-distance detection[1-2], anti-electromagnetic interference[3], and no need for power supply along the line, achieves precise sensing and positioning through the backward Rayleigh scattering mechanism of the optical time-domain reflectometer (OTDR) with optical fiber as the sensing medium. It has been widely applied in perimeter security across various fields such as railways[4-5], highways[6-7], bridges[8-10] and pipelines[11-12].
In recent years, researchers have developed various security identification models based on the DVS system. Jia et al. proposed an SVM-based temporal recognition method, achieving a 94% recognition rate for events such as noise, watering, and tapping.[13] Li et al. utilized transfer learning, reaching a 94.67% classification accuracy for 8 simulated events.[14] Mahmoud et al. designed a two-stage vibration pattern recognition scheme based on power spectrum estimation, with an intrusion detection rate exceeding 95% including false alarms.[15] Lyu et al. employed a classic CNN to learn two-dimensional image features of different events, achieving an average recognition rate of 97.67% for 6 types of disturbance events on fences.[16]
However, these mainstream models encounter critical bottlenecks in practical applications. With the development of edge computing and miniaturization of processors, existing models—including the aforementioned methods — suffer from drawbacks such as high computational resource consumption, strict hardware requirements, and elevated deployment costs. These issues fail to align with the current development characteristics of perimeter security, severely restricting the embedded application and commercialization of security identification systems on edge devices.[17]
To address these problems, researchers have proposed various lightweight neural network models. Among them, SqueezeNet reduces parameters through a squeeze-and-expand structure but exhibits weak performance in complex tasks.[18] ShuffleNet optimizes performance in medium-complexity tasks via channel shuffling yet faces challenges such as poor hardware adaptability and high computational overhead.[19] In contrast, the MobileNet series achieves a balance between lightweight design and high performance through the efficient computing logic of depthwise separable convolution, multi-version scene adaptability, and strong generalization ability in complex tasks, making it the mainstream choice for computer vision tasks on edge devices.[20-22]
Meanwhile, data dimensionality reduction is a key link in adapting to lightweight network operations.[23] Principal Component Analysis (PCA) maps high-dimensional data to a low-dimensional space through linear transformation but does not utilize category labels, easily introducing useless interference features and leading to high false alarm rates in classification tasks.[24-25] T-distributed Stochastic Neighbor Embedding (t-SNE) realizes non-linear mapping of high-dimensional data by constructing probability distributions of samples in the high-dimensional space and t-distributions in the low-dimensional space to maximize their similarity.[26-27] However, it suffers from extremely low computational efficiency and poor clustering stability, failing to stably distinguish between different event types with insufficient adaptability. In contrast, Linear Discriminant Analysis (LDA) generates classification-friendly low-dimensional features by maximizing inter-class differences and minimizing intra-class differences, perfectly matching the core requirements of the DVS system, such as real-time performance, anti-interference, small sample size, and high classification accuracy.[28-29]
Based on this, this paper innovatively proposes the LDA-MNV4 method, which organically combines the high-dimensional feature dimensionality reduction capability of LDA with the lightweight and efficient feature extraction capability of MobileNet-V4 (MNV4). It constructs an end-to-end processing framework from dimensionality reduction to feature enhancement and then to classification. While ensuring recognition accuracy, it significantly reduces computational overhead, providing an efficient solution for the deployment of DVS systems on edge devices.
2. Systems and Methods
2.1. Experimental System
The core of DVS system lies in the utilization of Phase-Sensitive Optical Time Domain Reflectometry (Φ-OTDR) technology to achieve distributed fiber optic vibration sensing.[30] This technology relies on the backward Rayleigh scattering mechanism of Optical Time Domain Reflectometry (OTDR) to realize precise perception of external environmental signals, demonstrating excellent distributed detection and positioning capabilities. By accurately measuring the scattered light power in the photodetector, OTDR can effectively capture external information at the location of the sensing fiber.[31-32]
The basic principle of DVS is that vibration signals induce changes in the phase of backward Rayleigh scattered light in the sensing fiber, and the phase information of the vibration signals is then demodulated and transmitted to the data acquisition card for collection. When external disturbance signals act on the sensing fiber, the Stress Effect, Photoelastic Effect, and Poisson Effect inside the fiber cause subtle changes in internal structures (such as length and refractive index). These changes in internal fiber parameters lead to variations in the phase Φ of the Rayleigh backward scattered light, ultimately manifesting as changes in the intensity of the scattered light within the fiber.
The Stress Effect is the source of the fiber’s ability to perceive external vibrations and serves as the prerequisite for the Photoelastic Effect and Poisson Effect. As an elastic body, the stress of the fiber follows Hooke’s Law, as shown in Equation 1. The strain expression describing the change in fiber length is given in Equation 2.
The expression of the axial length strain of the fiber is:
$\sigma$ denotes the stress generated inside the fiber. $E$ represents the elastic modulus of the fiber material. The $E$ of the quartz fiber used in the experiment is approximately 70 GPa. $\varepsilon$ is the axial strain of the fiber, reflecting the degree of length deformation. $\Delta L$ is the change in fiber length. $L_{0}$ is the original length of the fiber.
The expression of the photoelastic effect is Equation 3:
$\Delta n$ is the change in the fiber’s refractive index. $C$ is the photoelastic coefficient of the fiber material (the $C$ of quartz is approximately $3.1 \times 10^{-12} \text{ Pa}^{-1}$).
The expression of the poisson effect is Equation 4:
The expression for the transverse length strain of the fiber is:
$\nu$ is the Poisson’s ratio of the fiber material. The $\nu$ of quartz fiber is approximately 0.17. $\varepsilon'$ is the transverse strain of the fiber expressed in Equation 5. where $\Delta d$ is the change in fiber diameter and $d_{0}$ is the original radius of the fiber.
When external vibrations occur, stress is generated in the fiber. This stress is converted into axial strain via Equation 1, which on one hand triggers the Photoelastic Effect and on the other hand induces the Poisson Effect. Together, these effects cause phase changes in the backward Rayleigh scattered light. Finally, the phase Φ and intensity changes are captured by the PD and demodulated into vibration signals.
Figure 1 shows the principle of the OTDR, the principle of the DVS, and the diagram of the experimental system.
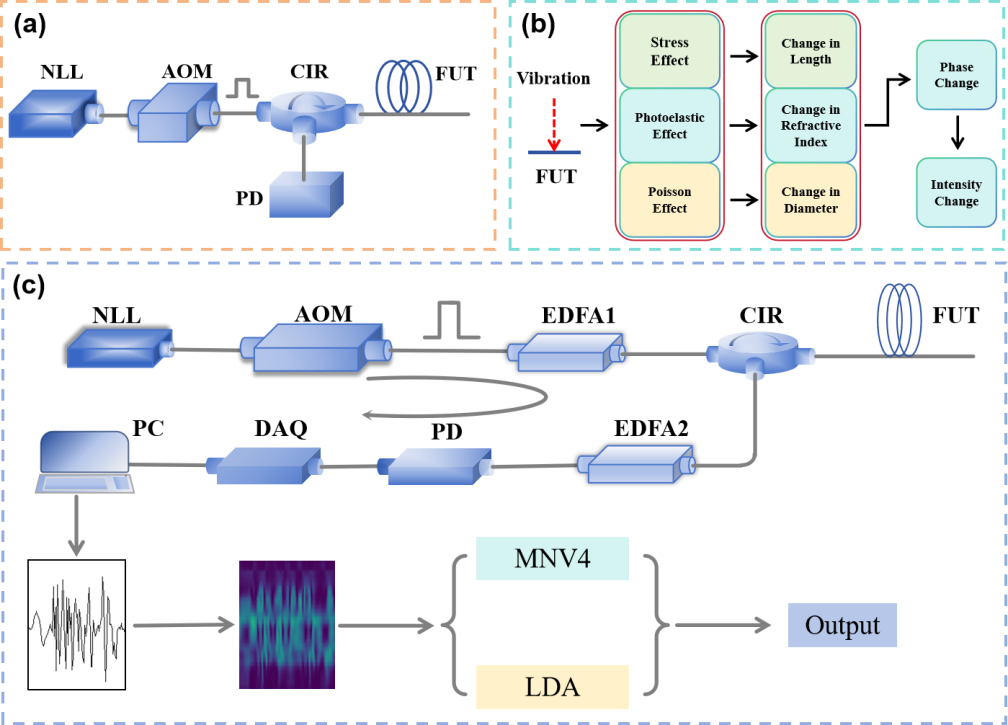
Figure 1. (a) OTDR Schematic Diagram. (b) Schematic Diagram of Vibration Signal Detection. (c) DVS Experimental System Diagram.
The system uses a narrow-linewidth laser (NLL) as the light source. The light is modulated into pulsed light by an acousto-optic modulator (AOM), then amplified by an erbium-doped fiber amplifier (EDFA) and transmitted to the fiber under test (FUT) via a circulator (CIR) to excite backward Rayleigh scattered light. The PD captures changes in the phase Φ and intensity of the light; the signal is then converted into a digital signal by the data acquisition card (DAQ) and transmitted to a computer for analysis.
2.2. Data Acquisition and Conversion
In the experiment, the DVS collected one-dimensional time-domain vibration signals at a scanning frequency of 2 kHz, including signals corresponding to three types of events: background noise, mechanical excavation, and human movement. A total of 6000 signal groups were collected to form a database (2000 groups for each event), which was divided into a training set and a validation set at a ratio of 7:3. Figure 2(a) shows the collected data signals within 1 second, which contain information about different events.
The DVS continuously collects vibration signals at various positions along the fiber in a time series. The 200-meter-long fiber was divided into 200 sampling points. Signals between 3 adjacent sampling points within 1 second were taken as a single data group and converted into a 2D image suitable for model input. As shown in Figure 2(b), this image is a standard 3-channel, 224×224-pixel image—sufficient to retain the spatiotemporal details of vibration signals without increasing computational load due to excessive size.
In the image, each row corresponds to the signal change at a fixed fiber position over different times. Each column corresponds to the signal distribution within 2 meters before and after the event occurrence location along the fiber at a specific moment. The shade of color represents the intensity of the signal.
Figure 2. Signal diagrams of the three types of events
2.3. Recognition Methods
This paper innovatively proposes the MNV4-LDA algorithm. Its core logic is to leverage the efficient network structure of MobileNet-V4 (MNV4) for deep extraction of data features, then utilize Linear Discriminant Analysis (LDA) to achieve lightweight compression of high-dimensional data while retaining key classification information, and finally perform recognition and classification of the low-dimensional features. The two components are optimized collaboratively to balance feature preservation and computational efficiency.
First, the 3×224×224 RGB images are input to MNV4. They are downsampled to 112×112 via a 3×3 initial convolution block, and then 1280-dimensional semantic features are extracted through depthwise separable convolution and inverted residual structures, instead of the original ultra-high-dimensional pixel features (exceeding 150,000 dimensions). This process extracts semantically discriminative low-dimensional features from low-resolution images rather than the original pixel-level ultra-high-dimensional features, followed by dimensionality reduction performed at the semantic feature layer. It significantly reduces the input dimension for dimensionality reduction.
Secondly, data dimensionality reduction is employed to enhance efficiency. Initially, Principal Component Analysis (PCA) is used to eliminate feature redundancy and reduce computational complexity. Then, supervised LDA is applied to strengthen inter-class discriminability. After LDA dimensionality reduction to 2 dimensions (the optimal dimension for 3-class classification), only one fully connected layer is used to complete 3-class classification, resulting in almost no additional computational overhead. This design reduces computational complexity through dual means: a lightweight network and feature-level dimensionality reduction. Meanwhile, the combination of semantic features and supervised dimensionality reduction ensures classification accuracy, ultimately achieving the goal of pattern recognition with low computation, high real-time performance, and high accuracy. As shown in Figure 3, the structure and flowchart of each part of the recognition model are presented.
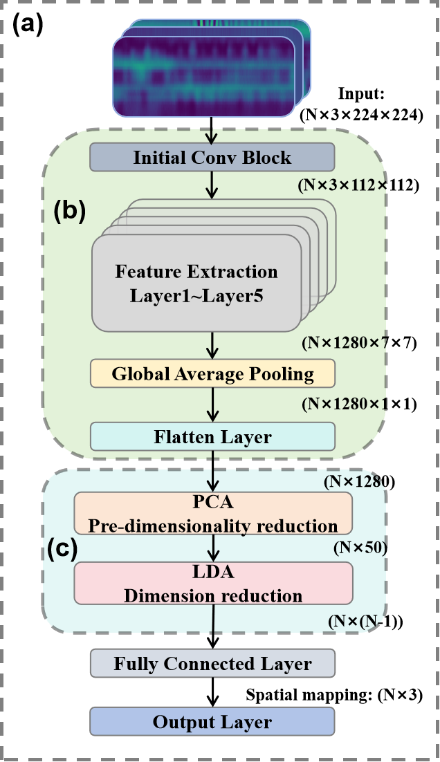
Figure 3. (a) Model structure and flowchart. (b) The MNV4 feature extraction process. (c) Dimensionality reduction process
The core of this recognition model is replacing the original neural network with a lightweight network and substituting pixel-level dimensionality reduction with feature-level dimensionality reduction, addressing the problems of large computational volume and low discriminability in high-dimensional data compression.
Pixel-level dimensionality reduction requires processing an N×150528 matrix, whereas this scheme only processes N×1280 more discriminative semantic features. The computational complexity of LDA is reduced by over 99% while inter-class differences are enhanced, ompensating for potential feature loss caused by MNV4. The calculated parameter count is only 2.38M, and the overall computational power meets the requirements for operation on edge devices.
3. Experiments and Analysis
3.1. Analysis of Preprocessing Results
In previous studies by other researchers, many have adopted denoising as a preprocessing step. Therefore, this experiment conducts denoising analysis on signals to explore the value and significance of denoising for the current study. Figure 4 presents the original time-domain waveform diagrams and the waveform diagrams after wavelet denoising for the three types of events.
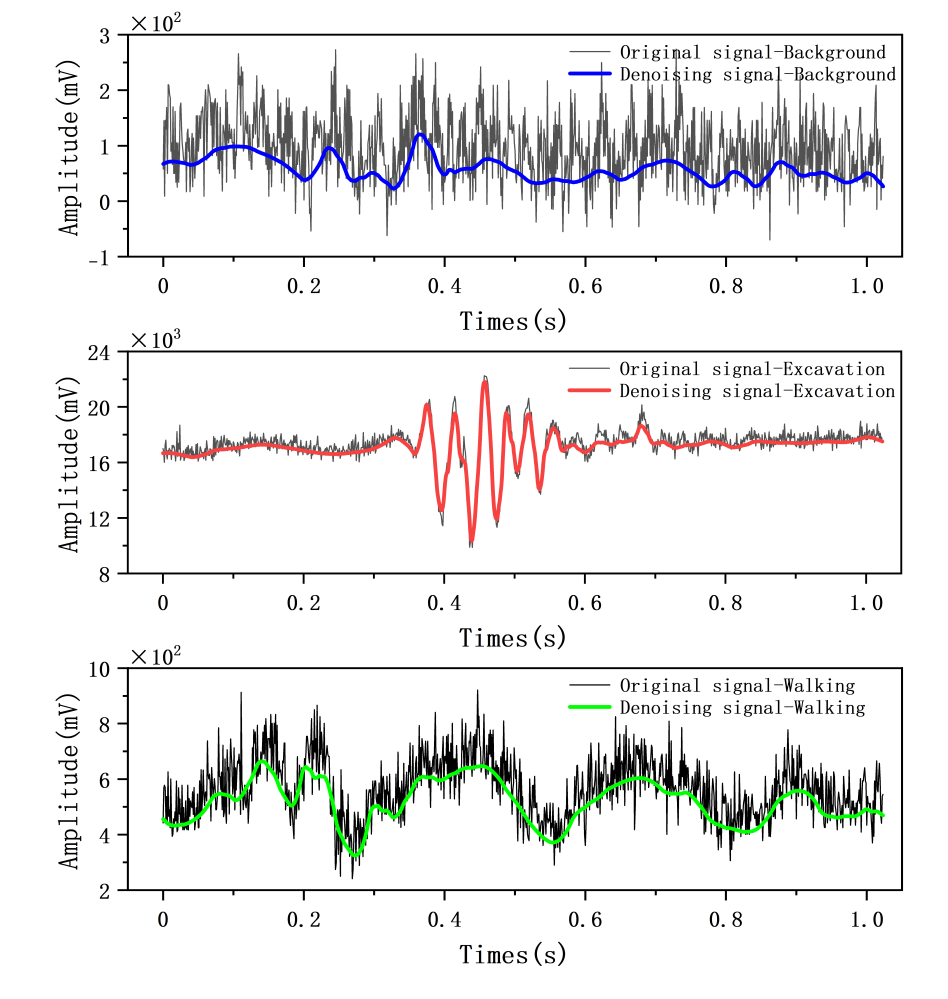
Figure 4. Comparison of Waveforms Before and After Denoising
The three types of events can be clearly distinguished from Figure 4.
For background noise: The original waveform shows dense, small-amplitude irregular fluctuations with significant noise interference; after denoising, the waveform becomes smoother and maintains a low amplitude overall.
For mechanical excavation: The original waveform is relatively stable in the front and rear segments, while the middle segment exhibits dense, large-amplitude oscillations due to sudden vibrations caused by excavation; after denoising, the contour of the oscillating segment becomes clearer.
For human walking: The original waveform shows continuous, intermittent undulations; after denoising, the periodicity of the fluctuations and the contour of peaks and valleys become more distinct.
Overall, wavelet denoising effectively filters out redundant noise from the original waveforms of each event while retaining and highlighting the core features of different event signals.
Separate models were trained using denoised and non-denoised data, and the relevant experimental indicators are shown in Table 1. Among them, Parameters and Floating-point Operations (FLOPs) are key indicators for measuring the model’s computational overhead, and are closely related to the model’s inference speed.
Table 1. Comparison of Results with and without Denoising
| Data Type | Parameters | FLOPs | Accuracy |
|---|---|---|---|
| With Denoising | 2.228M | 0.326 G | 98.89% |
| Without Denoising | 2.38M | 0.252 G | 98.28% |
Analysis shows that in this experiment, the denoising process increases computational overhead without achieving a significant improvement in accuracy. After comprehensive consideration, denoising is not adopted in this experiment.
3.2. Analysis of Dimensionality Reduction Capability
According to the principle of Linear Discriminant Analysis (LDA), the maximum dimensionality reduction dimension is one less than the number of categories. Since the dataset in this study includes 3 categories, the maximum dimensionality reduction dimension of LDA is 2. Therefore, dimensionality reduction was performed to 1 dimension and 2 dimensions respectively, and the results of each dimension were evaluated.
Multiple evaluation indicators were calculated under different dimensionality reduction dimensions, including the trace of between-class scatter matrix, trace of within-class scatter matrix, total variance, cross-validation accuracy, and F1-score. The specific results are shown in Table 2.
Table 2. Comparison of Dimensionality Reduction Dimension Indicators
| Dimensions | Inter-class dispersion trace | Intra-class dispersion trace | Total Variance | Cross-validation Accuracy | F1-score |
|---|---|---|---|---|---|
| 1 | 14386.50 | 4196.99 | 4.42 | 0.6112 | 0.6136 |
| 2 | 19073.14 | 8394.00 | 6.54 | 0.8702 | 0.8697 |
Comprehensive analysis of the above indicators reveals that although 1-dimensional reduction performs better in terms of within-class compactness, 2-dimensional reduction has obvious advantages in between-class discriminability, information retention, and classification performance. In particular, the cross-validation accuracy and F1-score are improved by more than 40%, indicating that 2-dimensional reduction can retain more feature information while significantly enhancing the model’s ability to recognize different categories. Therefore, the optimal dimensionality reduction dimension is determined to be 2.
To further verify the effectiveness of LDA dimensionality reduction, this experiment conducts a quantitative comparative analysis of the original features and the features after LDA dimensionality reduction from the perspective of inter-class distance. The events are defined as follows: background noise (Category 0), mechanical excavation (Category 1), and human walking (Category 2).
The inter-class distance is measured using the Euclidean distance to quantify the gap between the mean feature vectors of different categories. The formula is:
Where, $\mu_{1}$ and $\mu_{2}$ are the mean feature vectors of Category $i$ and Category $j$, respectively. The results are shown in Figure 5 below.
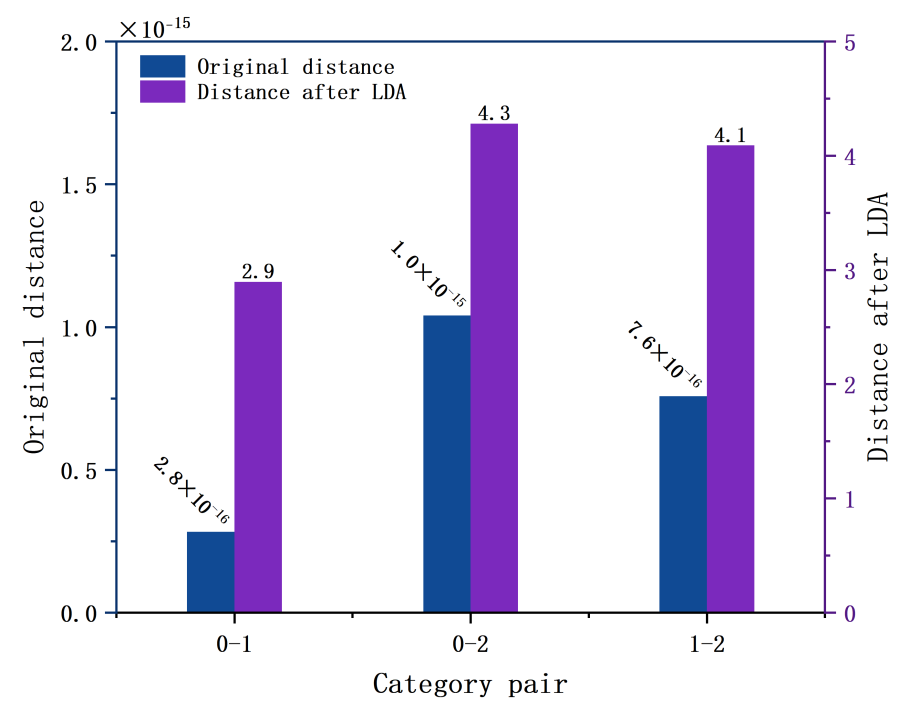
Figure 5. Comparison of Inter-class Distances Before and After Dimensionality Reduction
As can be seen from the figure, the inter-class distance of the original features is close to zero (on the order of 10-17). After dimensionality reduction, the inter-class distance is significantly increased to between 2.8 and 4.2, indicating that LDA effectively expands the inter-class discriminability. After LDA dimensionality reduction, the inter-class distances of all category pairs are significantly increased, demonstrating that the dimensionality reduction process effectively enhances the differentiation between categories.
3.3. Analysis of Recognition Results
In terms of model architecture, MobileNetV4-ConvSmall was selected due to its small model size and low memory usage. During training, the AdamW optimizer and CosineAnnealingLR learning rate scheduler were adopted to ensure stable and efficient model convergence. The experiment was conducted on a CPU platform (model: i5-13500). The dataset was used for inference analysis with the MNV4 and MNV4-LDA models respectively, and the number of parameters and inference speed were compared. The results are shown in Table 3.
Experimental data indicates that after LDA dimensionality reduction, the number of parameters is reduced from 632.22M to 2.38M, with a reduction rate of 99.6%—this significantly saves computational resources and contributes prominently to the improvement of the experiment’s real-time performance. Meanwhile, the single-sample processing time of MNV4-LDA on the CPU is 127.0ms, which is 3 times faster than that of MNV4.
Table 3. Comparative Analysis of Different Models
| Model | Parameters | i5-13500 |
|---|---|---|
| MNV4 | 632.22M | 450.3ms |
| LDA-MNV4 | 2.38M | 127.0ms |
The recognition results on the 6000-group dataset are shown in Figure 6. Compared with MNV4, the recognition accuracy of MNV4-LDA increases from 93.61% to 98.28% (an improvement of 4.67%), and the inference time decreases from 450.3ms per sample to 127.0ms per sample—achieving a dual breakthrough in accuracy and efficiency.
Figure 6. Comparison of Recognition Results
(a) Recognition results of LDA-MNV4. (b) Recognition results of MNV4
4. Conclusion
To address the contradiction between computational overhead and accuracy in the edge deployment of DVS, this paper proposes the MNV4-LDA end-to-end method, which integrates the lightweight feature extraction capability of MNV4 and the advantages of supervised dimensionality reduction of LDA. Experiments show that the number of parameters of the method is reduced from 632.22M to 2.38M, with a reduction rate exceeding 99.6%. Its recognition accuracy reaches 98.28%, which is 4.67% higher than that of MNV4, and the single-sample inference time on the CPU is 127.0ms, 3 times faster than MNV4. Notably, the method ensures high accuracy without the need for a signal denoising algorithm, effectively solving the deployment challenges of traditional models and balancing efficiency and stability. It provides a practical solution for the edge application of DVS systems in perimeter security.In future work, the dataset and event types can be expanded to improve the adaptability of the method to complex scenarios.
Author Contributions
Zhaohai Li designed the experiment and wrote the report. Zhenzhen Zhang participated in the design and review process. Jiaxing Tang reviews the article. Sheng Huang and Wenan Zhao provide technical support. Chen Wang and Ying Shang were involved in guidance and project management.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgements
This work was supported in part by Key R&D Program of Shandong Province, China under Grant 2025CXGC011107 and 2025JMRH0108, HY action project under Grant JK2023B0316A, New twenty policies for university of Jinan City under Grant 202333014, Central Guiding Local Science and Technology Development Fund in Shandong Province under Grant YDZX2024042, Major Innovation Project of the Pilot Program for the Integration of Education, Research and Industry of Qilu University of Technology under Grant 2025ZDZX13.
Reference
[1] Y. Kong, Y. Liu, Y. Shi, F. Ansari, T. Taylor. “Research on the ϕ-OTDR fiber sensor sensitive for all of the distance.” Opt. Commun. 2018, 407, 148-52.
[2] Y. Bai, J. Xing, F. Xie, S. Liu, J. Li. “Detection and identification of external intrusion signals from 33 km optical fiber sensing system based on deep learning.” Opt. Fiber Technol. 2019, 53.
[3] J. Wang, H.-Y. Man, C. Meng, P. Liu, S. Li, H.-S. Kwok, Y. Zi. “A fully self-powered, natural-light-enabled fiber-optic vibration sensing solution.” SusMat 2021, 1, 4, 593-602.
[4] H. Meng, S. Wang, C. Gao, F. Liu. “Research on recognition method of railway perimeter intrusions based on Φ-OTDR optical fiber sensing technology.” IEEE Sensors J. 2021, 21, 8, 9852-59.
[5] Y. Yan, T. Li, J. Liu, W. Wang, Q. Su. “Monitoring and early warning method for a rockfall along railways based on vibration signal characteristics.” Sci. Rep. 2019, 9, 1, 6606.
[6] Y. Khacef, M. van den Ende, C. Richard, A. Ferrari, A. Sladen. “Precision traffic monitoring: leveraging distributed acoustic sensing and deep neural networks.” IEEE Trans. Intell. Transp. Syst. 2025, 26, 6, 7678-89.
[7] J. Yi, Y. Shang, C. Wang, Y. Du, J. Yang, M. Sun, S. Huang, S. Qu, W. Zhao, Y. Zhao, J. Ni. “An intelligent crash recognition method based on 1DResNet-SVM with distributed vibration sensors.” Opt. Commun. 2023, 536, 129263.
[8] S. Zhao, R. Zhou, M. Luo, J. Liu, X. Liu, T. Zhou. “Distributed fiber optic sensing system for vibration monitoring of 3D printed bridges.” Optoelectron. Lett. 2025, 21, 1, 28-34.
[9] P. Xiang, X. Xie, X. Zhang, H. Wu, Z. Chen, L. Wang, X. Liu, D. Yang, H. Wang. “Quasi-distributed optical fiber sensing for the coupled vibration analysis of high-speed train-bridge coupled system under earthquakes.” Sens. Actuators, A 2024, 374, 115422.
[10] X. W. Ye, Y. Q. Ni, K. Y. Wong, J. M. Ko. “Statistical analysis of stress spectra for fatigue life assessment of steel bridges with structural health monitoring data.” Eng. Struct. 2012, 45, 166-76.
[11] L. Ren, T. Jiang, Z. Jia, D. Li, C. Yuan, H. Li. “Pipeline corrosion and leakage monitoring based on the distributed optical fiber sensing technology.” Measurement 2018, 122, 57-65.
[12] C. Zhang, S. Liu, W. Zhao, L. Dong, Y. Zhang, C. Wang, S. Qu, C. Yao, J. Lv, S. Li, Q. Zhao, Y. Shang, G. Liu, J. Ni. “Study on vibration signals identification method for pipeline leakage detection based on deep learning technology.” Opt. Commun. 2024, 565, 130588.
[13] H. Jia, S. Liang, S. Lou, X. Sheng. “A k -nearest neighbor algorithm-based near category support vector machine method for event identification of φ -OTDR.” IEEE Sensors J. 2019, 19, 10, 3683–89.
[14] Y. Li, X. Zeng, Y. Shi. “Quickly build a high-precision classifier for Φ-OTDR sensing system based on transfer learning and support vector machine.” Opt. Fiber Technol. 2022, 70, 102868.
[15] S. S. Mahmoud. “Practical aspects of perimeter intrusion detection and nuisance suppression for distributed fiber-optic sensors.” IEEE Trans. Instrum. Meas. 2023, 72, 1–11.
[16] C. Lyu, Z. Huo, X. Cheng, J. Jiang, A. Alimasi, H. Liu. “Distributed optical fiber sensing intrusion pattern recognition based on GAF and CNN.” J. Lightwave Technol. 2020, 38, 15, 4174–82.
[17] M. Sharma, A. Tomar, A. Hazra. “Edge computing for industry 5.0: fundamental, applications, and research challenges.” IEEE Internet Things J. 2024, 11, 11, 19070–93.
[18] X. Zhu, Z. Feng, Y. Fan, J. Ma. “A multiple-blockage identification scheme for buried pipeline via acoustic signature model and SqueezeNet.” Measurement 2022, 202, 111671.
[19] N. Ma, X. Zhang, H.-T. Zheng, J. Sun. “ShuffleNet V2: practical guidelines for efficient CNN architecture design.”European Conference on Computer Vision (ECCV). 2018, 122–38.
[20] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L.-C. Chen. “MobileNetV2: inverted residuals and linear bottlenecks.”Computer Vision and Pattern Recognition (CVPR). 2018, 4510–20.
[21] A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y. Zhu, R. Pang, V. Vasudevan, Q. V. Le, H. Adam. “Searching for MobileNetV3.” International Conference on Computer Vision (ICCV).2019, 1314–24.
[22] J. Guan, B. Lin, Q. Tan. “Skin cancer image classification based on MobileNet-V4 with composite data augmentation.”Computer Vision, Image and Deep Learning (CVIDL). 2025, 184–88.
[23] R. Rani, M. Khurana, A. Kumar, N. Kumar. “Big data dimensionality reduction techniques in IoT: review, applications and open research challenges.” Cluster Comput. 2022, 25, 6, 4027–49.
[24] T. Meng, H. Shi, C. Wang, B. Wu. “Application of principal component analysis in measurement of flow fluctuation.” Measurement 2021, 173, 108503.
[25] M. Greenacre, P. J. F. Groenen, T. Hastie, A. I. D’Enza, A. Markos, E. Tuzhilina. “Principal component analysis.” Nat. Rev. Methods Primers 2022, 2, 1, 100.
[26] B. H. Meyer, A. T. R. Pozo, W. M. Nunan Zola. “Global and local structure preserving GPU t-SNE methods for large-scale applications.” Expert Syst. Appl. 2022, 201, 116918.
[27] A. Li, C. Feng, S. Xu, Y. Cheng. “Graph t-SNE multi-view autoencoder for joint clustering and completion of incomplete multi-view data.” Knowledge-Based Syst. 2024, 284, 111324.
[28] Z. Li, F. Nie, D. Wu, Z. Wang, X. Li. “Sparse trace ratio LDA for supervised feature selection.” IEEE Trans. Cybern. 2024, 54, 4, 2420–33.
[29] H. Zhou, S. Gao, Y. Xie, C. Zhang, J. Liu. “Multi-condition wear prediction and assessment of milling cutters based on linear discriminant analysis and ensemble methods.” Measurement 2023, 216, 112900.
[30] P. Ma, Z. Sun, K. Liu, J. Jiang, S. Wang, L. Zhang, L. Weng, Z. Xu, T. Liu. “Distributed fiber optic vibration sensing with wide dynamic range, high frequency response, and multi-points accurate location.” Opt. Laser Technol. 2020, 124, 105966.
[31] L. Lu, M. Yong, Q. Wang, X. Bu, Q. Gao. “A hybrid distributed optical fiber vibration and temperature sensor based on optical rayleigh and raman scattering.” Opt. Commun. 2023, 529, 129096.
[32] L. Huang, X. Fan, Z. He. “Hybrid distributed fiber-optic sensing system by using rayleigh backscattering lightwave as probe of stimulated brillouin scattering.” J. Lightwave Technol. 2023, 41, 13, 4374–80.